Fuzzing for eBPF JIT bugs in the Linux kernel

Inspired by Manfred Paul‘s amazing write-up of an eBPF JIT verifier bug, I wanted to find out if there have been any significant changes to the Linux eBPF verifier since the publication of Manfred’s bug and if there was an easy way to fuzz the verifier.
As it turns outs, the commit that fixed the issue reported by Manfred earlier this year introduced a new bug into the verifier, namely CVE-2020-27194.
This blog post will lay out the architecture of the fuzzer I wrote for Linux eBPF, as well as the design of the custom generator I wrote. I will publish the code for the fuzzer, as well as an exploit PoC for the bug I discovered after some time has passed. At the time of writing, the bug is still unpatched in Ubuntu 20.10.
If you are unfamiliar with BPF, I recommend reading the write-up I linked above before continuing with this blog post.
Also, feel free to just skip to the vulnerability breakdown of CVE-2020-27194 directly.
Existing projects⌗
Before I started coding, I got my hands on previous projects about fuzzing the eBPF JIT verifier. I found out, that a fuzzer for this has already been written and published in this GitHub repository.
To quote from the repository’s page:
The motivation of this project is to test verifier in userspace so that we can take advantage of llvm’s sanitizer and fuzzer framework.
I thought about why the creators of this project would want to go through the trouble of compiling a complex kernel component into a user-space program, and not just use an existing solution such as Syzkaller. I came up with the following two reasons:
- The kernel can be very slow in comparison to user-space, especially when taking into account how much time it takes to perform context-switches and the lack of control over, for example, the memory allocator
- The BPF verifier, including the JIT compiler, are protected by a mutex and thus will scale really badly if you want to run this fuzzer on more than one core
Let’s go through compiling calling kernel functions in user-space programs through hooking, as it is a technique this fuzzer will use.
Compiling kernel components into user-space programs⌗
The approach of the developers of the mentioned BPF fuzzer was to use the kernel build system and header files to first generate processed source code files of the code that contains the eBPF verifier and its main routine, bpf_check(). What this means is simply that the compiler won’t actually compile anything, but it will process macros and includes of header files and write the resulting, “raw”, source code into processed .i files.
The reason for this step is to obtain declarations of all kernel symbols the verifier references and to be able to easily compile the resulting files into user-space objects, which is the next step.
A minimal example of generating such a .i file of a Linux source code file could look like this:
KERNEL_SRC=/path/to/kernel/to/fuzz-test
process_example:
cd $(KERNEL_SRC) && \
make HOSTCC=clang CC=clang kernel/bpf/verifier.i
The advantage of using the Linux build-system is that this step is quite simple.
The next step is actually compiling each of the .i files that were generated into an object file and linking them together. This is the step where it gets a little more complicated. Although we obtained declarations for all symbols used by the verifier in the first step, it does not actually mean that we obtained all definitions.
As an example, the verifier is likely to include header files that declare kernel allocator functions such as kmalloc(). However, the definition of kmalloc() resides in an entirely different subsystem of the kernel and thus the linker won’t be able to successfully link the object files of the verifier.
To solve this problem, the authors of the BPF fuzzer wrote user-space hooks, which simply means they implemented, for example, the kmalloc() call themselves. In the case of kmalloc(), they simply called the user-space standard function malloc() within the definition of the kmalloc() function. Here is an example:
void *kmalloc(size_t size, unsigned int flags)
{
return malloc(size);
}
As long as the behavior is the same (return a pointer to the newly allocated block or return an error pointer), this “hook” of the kmalloc() function is invisible to the BPF verifier which will run in user-space. The compiler can then link this function with the object files of the BPF verifier and succeed.
The process of hooking every single undefined reference in the verifier is tiresome but will massively pay off due to the performance benefits it yields.
How this fuzzer differs from existing projects⌗
I roughly broke down the process of compiling kernel components into user-space programs. This is a very interesting approach used by the authors of the existing project I mentioned above since they were now able to simply use libfuzzer to fuzz the BPF verifier itself.
However, my goal was not to find bugs such as memory corruption within the verifier code but to find logical JIT flaws, such as the verifier believing a memory store operation is in bounds and thus safe although it might not be.
For this goal, it is not sufficient to call the BPF verifier routine in a loop and wait for a crash. Instead, the execution flow for a single input would have to be something like the following:
- Generate or mutate a BPF program
- Run the BPF verifier against it
- If the program is valid, triage it by calling the actual bpf() system call and loading the program
- Trigger the program and have a mechanism in place to check for bugs Repeat
- Such a flow could be illustrated as follows:
The architecture of this fuzzer⌗
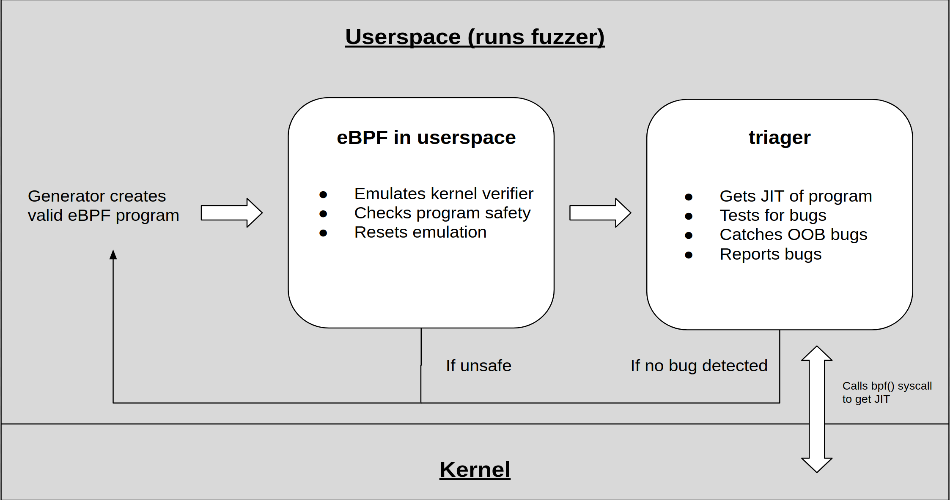
In order to efficiently implement the execution flow I mentioned above I decided to go with an approach that would let me scale as much as possible.
For this reason, I wrote a manager. The manager is responsible for starting up a number of Virtual Machines running the Linux kernel to be tested. The manager would then connect to the VMs through SSH and execute a number of eBPF fuzzer processes. Each fuzzer process runs its own generator and feeds them to the BPF verifier in user-space. If the generated input is valid, the fuzzer will load the BPF program through the bpf() system call and trigger the program’s execution. It will then use a bug detection mechanism to check if the program was indeed safe.
Bug detection⌗
It is a difficult problem to detect JIT bugs, as they may occur without crashing the kernel. An example of this would be the verifier being confident that a branch is always going to be entered, even though it might not be.
One solution to this problem would be to extend the JIT with run-time assertions. However, I went with a simpler approach.
My goal was to find faulty pointer arithmetic, meaning bugs that make the verifier believe a memory load or store is in bounds although it might not be.
For this reason, the bug detection works roughly like this:
- a BPF map is loaded and a pointer to it moved into a register
- a random number of BPF ALU and Branching operations are performed on one or more registers
- one or more pointer arithmetic operations must be performed on the pointer to the map with a register that had its state changed through an operation
- a random value is written to the map the pointer points at
If the BPF verifier runs through the program and is confident that it is safe, then I will have a guarantee that no matter which values the registers I perform random ALU operations on and then add to or subtract from the map pointer have, the memory operation is always in bounds, meaning the value of the map has to change.
Thus, if the contents of the map I used for testing have not changed after triggering the BPF program in question, I know that the fuzzer wrote somewhere into memory but not into the map and thus faulty pointer arithmetic was detected.
The input generator⌗
Again, if you are unfamiliar with BPF and the following sections don’t make sense, I recommend reading Manfred Paul’s write up and returning here.
Program validity vs Program safety⌗
I decided to write a generator from scratch instead of having a structure unaware fuzzer such as libfuzzer perform mutation and generation. The reason for this is that although through coverage guided feedback, libfuzzer should be able to generate valid programs at some point, even complex ones given a corpus of inputs, a large majority of mutated inputs won’t be valid.
A BPF program is valid if it follows the rules of the BPF language, e.g. reserved fields must be 0. Another rule is that conditional jumps must jump forward and have to be in bounds. Another rule states that a register has to be initialized before it can be read. The point is, BPF programs are highly structured and stateful. In such a case, a coverage-guided fuzzer that treats inputs as a binary blob and does not detect invalid states is not the most efficient solution.
By writing a custom generator, it is possible to always generate valid inputs and follow all the rules of BPF programs. The verifier might still reject the program if the verifier considers the program to be unsafe, but the program will always pass basic checks such as reserved fields not being set or only using valid registers.
Register states⌗
In order to write a generator for a state machine such as the BPF verifier, it must be aware of possible states to some degree. I mentioned register states earlier, so I wanted to break down what is really going on.
BPF supports 10 registers: BPF_REG_1 – BPF_REG_10.
In the case of a BPF program being used as a packet filter and the program is triggered through an incoming packet, the program will be executed and the registers R1 and R10 will be the only initialized registers. BPF_REG_R1 is a pointer to the incoming packet, whereas BPF_REG_R10 is a pointer to a stack frame for this BPF program’s execution. All the other registers are uninitialized at the point of entry into the program, but can take on any of the states listed below:
NOT_INIT: The default state of a register. It can’t be read
SCALAR_VALUE: The register contains a scalar value. This value can either be a known constant or it can be a range, for example, 1 – 5.
PTR_TO_MAP_VALUE_OR_NULL: The register could contain a pointer to a map or it could be NULL. In order to use the pointer, a check has to be performed to test if the pointer is NULL or not.
PTR_TO_MAP_VALUE: A register containing a pointer to a map that has been successfully checked. It can be used to read and write to the map.
There are actually more states, but they are not relevant to us right now. With this knowledge in mind, we can proceed by discussing the generator.
Using BPF skeleton programs for the generator⌗
I mentioned earlier that in order to effectively fuzz for eBPF programs that produce JIT bugs and to be able to detect them, some instructions must be present in every test case. For this reason, I designed the generator to produce inputs that consist of a header, a body, and a footer.
The header⌗
Since we want to test for improper pointer arithmetic verification, we will need to obtain a pointer to a BPF map which we can read from and later write into. This is a part of a test case that must always be present and can be considered to be initialization, thus it belongs in the header and is statically generated with the following BPF instructions:
// prepare the stack for map_lookup_elem
BPF_MOV64_IMM(BPF_REG_0, 0),
BPF_STX_MEM(BPF_W, BPF_REG_10, BPF_REG_0, -4),
BPF_MOV64_REG(BPF_REG_2, BPF_REG_10),
BPF_ALU64_IMM(BPF_ADD, BPF_REG_2, -4),
// make the call to map_lookup_elem
BPF_LD_MAP_FD(BPF_REG_1, BPF_TRIAGE_MAP_FD),
BPF_RAW_INSN(BPF_JMP | BPF_CALL, 0, 0, 0, BPF_FUNC_map_lookup_elem),
// verify the map so that we can use it
BPF_JMP_IMM(BPF_JNE, BPF_REG_0, 0, 1),
BPF_EXIT_INSN(),
With this operation performed, we can now use BPF_REG_0 as a pointer to a map and can use it whenever we want to generate pointer arithmetic.
I then wrote code that will initialize two registers with unknown values by reading them from the map:
BPF_LDX_MEM(BPF_DW, this->reg1, BPF_REG_0, 0),
BPF_LDX_MEM(BPF_DW, this->reg2, BPF_REG_0, 8),
Here, two registers are initialized using a 64bit read from the map. This changes their state from NOT_INIT to SCALAR_VALUE. At this point, the registers’ values could be anywhere in the range of 0 to 2**64, since it is a 64bit register. An alternative to loading two unknown values from a map would be to simply generate an instruction that loads a random immediate into a register.
In order to give the registers some bounds that are close to the map size of the program that will be tested, the next step of the header is to generate conditional jumps to set minimum and maximum value for the two registers.
Here is the function that generates the minimum bounds for a register:
inline struct bpf_insn input::generate_min_bounds(unsigned reg, int64_t val)
{
bool is64bit = this->rg->one_of(2);
this->min_bound = val == -1 ? this->rg->rand_int_range(-FUZZ_MAP_SIZE, FUZZ_MAP_SIZE): val;
if (is64bit)
return BPF_JMP_IMM(BPF_JSGT, reg, this->min_bound, 1);
else
return BPF_JMP32_IMM(BPF_JSGT, reg, this->min_bound, 1);
}
As you can see, all it does is generate a conditional jump that is true when the value is larger than the minimum bound that was randomly generated in the range of -FUZZ_MAP_SIZE and FUZZ_MAP_SIZE, which I set to 8192.
The body⌗
The header has initialized two registers with either a constant or with a value in the range close to the size of the map. The body is now responsible for generating a random amount of ALU operations on those two registers.
The body works in a loop and simply chooses two registers that are available for ALU or Branching instructions and then generates a random instruction:
for (size_t i = 0; i < num_instr; i++) {
int reg1, reg2;
this->chose_registers(®1, ®2);
if (rg->n_out_of(8, 10) || i == this->num_instr - 1) {
alu_instr a;
a.generate(this->rg, reg1, reg2);
this->instructions[index++] = a.instr;
}
else {
branch_instr b(this->header_size, this->header_size + this->num_instr, index);
b.generate(this->rg, reg1, reg2);
this->instructions[index++] = b.instr;
generated_branch = true;
}
}
The generation of instructions is quite simple. In the case of an ALU operation, it will randomly choose one of the available instructions such as BPF_ADD, BPF_MUL, BPF_XOR etc. It will then decide which register will be the source and which will be the destination register of the operation. Lastly, it will simply return the generated BPF instruction.
A branching instruction works similarly, it will just choose one of the available branching opcodes and either use the second register or an immediate. It is aware of the size of the program and the index the instruction is located at and thus will always generate a branching instruction that is valid.
The footer⌗
In order to guarantee that each input will actually perform a memory write into the map, the footer will choose one of the two modified registers and then generate a pointer arithmetic instruction based on it. This generation has the same logic as generating an ALU instruction but limited to addition and subtraction as these are the only two allowed pointer arithmetic operations.
void range_input::generate_footer()
{
size_t index = this->header_size + this->num_instr;
// generate the random pointer arithmetic with one of the registers
int reg1, reg2 = -1;
this->chose_registers(®1, ®2);
alu_instr ptr_ar;
ptr_ar.generate_ptr_ar(this->rg, BPF_REG_4, reg1);
this->instructions[index++] = ptr_ar.instr;
this->instructions[index++] = this->generate_mem_access(BPF_REG_4);
this->instructions[index++] = BPF_MOV64_IMM(BPF_REG_0, 1);
this->instructions[index++] = BPF_EXIT_INSN();
}
It will then actually perform the memory operation and finally move the immediate one into BPF_REG_0 to ensure we have a valid return value and then exits.
Conclusion of the Fuzzer⌗
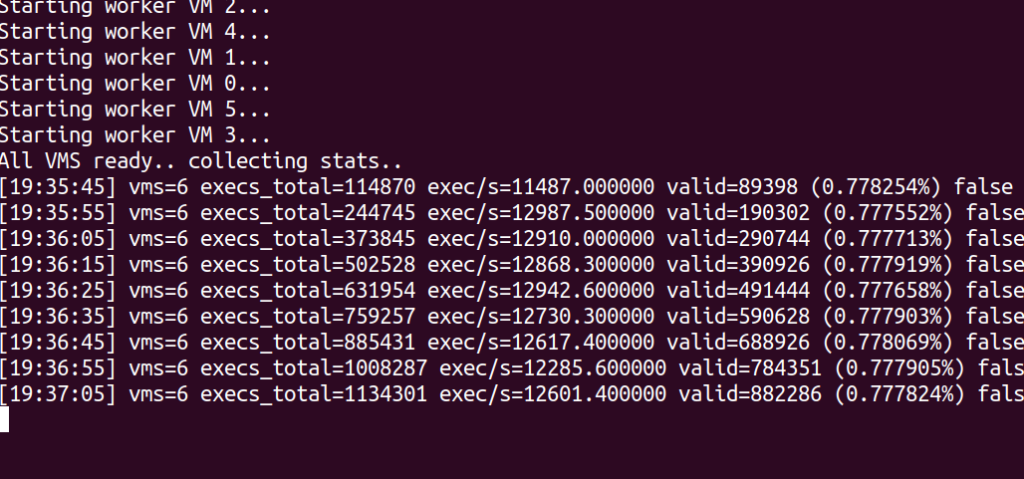
The above screenshot shows the output of the fuzzer when fuzzing with 6 VMs. In this case, each VM generates, verifies, triages, and tests around 1200 programs per second. At the time of writing, around 0.77% of programs generated are considered valid and are thus tested. It is important to note that most of the fuzzing time is spent testing the programs, so the kernel is the bottleneck here. The next step would be to actually execute the resulting JIT of the program in user-space to avoid interacting with the kernel altogether, which should result in a massive speedup.
A result of fuzzing and debugging this fuzzer is CVE-2020-27194, a BPF verifier bug in the OR ALU operation that can be leveraged into a full LPE exploit.
CVE-2020-27194: Vulnerability break down⌗
Background⌗
The verifier goes through each instruction and keeps track of possible changes to the state of a register. Let’s say a register is known the be in the range of 0 – 8192. If you add a constant of 100 to it, the new known range is 100 – 8292. For each ALU operation, there is a scalar_min_max.* function, which takes the two registers for this operation as arguments (if the operation is performed with an immediate, a register with a constant value is created for the immediate) and then checks if it can safely perform the operation and if it can be confident about knowing the destination register’s known values after the operation.
Here is the snippet of the scalar_min_max_or() function, that is used to track the ranges of a register after a binary OR operation has been performed on it.
static void scalar_min_max_or(struct bpf_reg_state *dst_reg,
struct bpf_reg_state *src_reg)
{
bool src_known = tnum_is_const(src_reg->var_off);
bool dst_known = tnum_is_const(dst_reg->var_off);
s64 smin_val = src_reg->smin_value;
u64 umin_val = src_reg->umin_value;
if (src_known && dst_known) {
__mark_reg_known(dst_reg, dst_reg->var_off.value |
src_reg->var_off.value);
return;
}
/* We get our maximum from the var_off, and our minimum is the
* maximum of the operands' minima
*/
dst_reg->umin_value = max(dst_reg->umin_value, umin_val);
dst_reg->umax_value = dst_reg->var_off.value | dst_reg->var_off.mask;
if (dst_reg->smin_value < 0 || smin_val < 0) {
/* Lose signed bounds when ORing negative numbers,
* ain't nobody got time for that.
*/
dst_reg->smin_value = S64_MIN;
dst_reg->smax_value = S64_MAX;
} else {
/* ORing two positives gives a positive, so safe to
* cast result into s64.
*/
dst_reg->smin_value = dst_reg->umin_value;
dst_reg->smax_value = dst_reg->umax_value;
}
/* We may learn something more from the var_off */
__update_reg_bounds(dst_reg);
}
As you can see, the arguments to the function are simply pointers to a struct representing the state of a register at this point of the verification for both the destination and source register.
If both registers are constants, no range tracking needs to be performed and the two values can simply be OR‘d and the result stored in the destination register.
However, if one of the two registers is known to have a range of possible values, it gets a little more complex.
Before we go into the details, I want you to notice which fields of the struct bpf_reg_state are accessed, namely smin, smax, umin and umax. These fields contain the signed and unsigned minimum and maximum value of a register.
All the tracking function does is determine that the new smallest possible value of the destination register is the largest value of the minimum values of the two OR operands.
The new largest possible value is the result of an OR of all bits that could possibly be set in both the destination and source operand.
Please note that both of these calculations are performed on the 64bit unsigned minimum and maximum values of both registers.
After these calculations are performed, the function checks if either of the two registers involved has a negative value by checking if the signed minimum value is smaller than 0. If so, it will just bail on the signed range tracking.
If both registers contain a positive number, the unsigned result of the calculation is simply cast into the signed register ranges.
Root cause of CVE-2020-27194⌗
Since there are 32bit ALU and Branching variants for each BPF instruction, special precaution must be taken as there might be some miscalculations when deriving a 32bit range from a 64bit register. Very roughly speaking, this is how Manfred Paul’s bug worked: An error is made when trying to derive a 32bit value during a branching instruction. This resulted in the verifier being incorrect about which range of possible values the falsely derived 32bit register can have.
To patch the issue and prevent such errors, commit 3f50f132d8400e129fc9eb68b5020167ef80a244 was pushed into the upstream kernel. It extended range tracking by adding 32bit variants of smin, smax, umin and umax to the struct bpf_reg_state. It also added 32bit versions of each of the scalar_min_max.* functions. This means 32bit and 64bit values are now tracked separately to some extent.
Generally speaking, the 32bit versions of those tracking functions follow the exact same logic as their 64bit counterparts, the only difference is that the 32bit register states are used.
This pattern is broken in the scalar32_min_max_or() function. When we went through the scalar_min_max_or() function (the 64bit variant), I noted that the last step was to cast the new unsigned values into the signed min and max values. The broken 32bit variant of this function does the same but writes the 64bit unsigned min and max values into the 32bit signed min and max values:
/* ORing two positives gives a positive, so safe to
* cast result into s64.
*/
dst_reg->s32_min_value = dst_reg->umin_value;
dst_reg->s32_max_value = dst_reg->umax_value;
This does not make any sense as 32bit and 64bit tracking should now be separate from each other. A bold theory of mine is that when explicit 32bit tracking functions were added, they were simply copied and pasted and the registers just changed to the 32bit fields since the logic is the exact same just with 32bit registers. My theory is that the authors simply forgot to change the 64bit umin and umax fields to their 32bit counterparts when they copy & pasted. The comment above those two lines, which suggests that it is safe to cast the unsigned values into a 64 bit signed value supports this claim as this is the same comment in the 64bit variant and makes no sense since this is a 32bit function. I am surprised this bug went unnoticed.
Triggering the bug⌗
I triggered this bug by storing the value 2 in a map and storing it inside a register.
I then used a 64bit conditional jump to guarantee that the value in unsigned mode is at least 1:
// Load the value from the map
BPF_LDX_MEM(BPF_DW, BPF_REG_5, BPF_REG_4, 0),
// Set the umin value of the derived value to 1.
BPF_JMP_IMM(BPF_JGT, BPF_REG_5, 0, 1),
BPF_EXIT_INSN(),
BPF_REG_5 now contains the value 2 and the verifier knows that in 32bit, as well as 64bit mode the minimum value is unsigned 1.
I then set the unsigned, 64bit maximum value to 25769803777. The binary representation lof this value is 0b11000000000000000000000000000000001. In unsigned 64bit range tracking, the range is now 1 to 25769803777.
BPF_LD_IMM64(BPF_REG_6, 25769803778UL),
BPF_JMP_REG(BPF_JLT, BPF_REG_5, BPF_REG_6, 1),
BPF_EXIT_INSN(),
The verifier will correctly detect that the 64bit range overflows into the 32bit range and thus it doesn’t know anything about the 32bit range, except for the minimum value being 1.
However, through the bug in the scalar32_min_max_or() function the signed 64bit unsigned range will be truncated into the signed 32bit range.
BPF_ALU64_IMM(BPF_OR, BPF_REG_5, 0),
BPF_MOV32_REG(BPF_REG_7, BPF_REG_5),
After the two operations above, the verifier believes that the 32bit range is of the minimum value 1 and maximum value 1, making it believe the register has the constant value 1. However, this is incorrect as the value could have been 2, as it is in our case.
After shifting BPF_REG_7 to the right by one, the verifier is certain that it contains the constant value 0, although that is incorrect and now contains the value 1. This means BPF_REG_7 can be multiplied by an arbitrary value and added to the map pointer. Since the verifier is confident that its value is 0, it will always allow the pointer arithmetic.
BPF_ALU64_IMM(BPF_RSH, BPF_REG_7, 1),
Patch⌗
A fix for this issue is available. The fix is to just use the correct 32bit registers. The fix comes with commit 5b9fbeb75b6a98955f628e205ac26689bcb1383e upstream.
The patch has been included in the stable kernel 5.8.15. Ubuntu 20.10, at the time of writing, runs on kernel 5.8.0.26. Although the patch was made available while Ubuntu 20.10 was still in beta, it has not yet been backported.
Exploit⌗
I have written an exploit that uses this bug for Ubuntu 20.10. The bug has been introduced with the 5.8.x kernel branch. Luckily, only a few distributions use this branch and if they are already released, they are out of beta for just a couple of weeks. The exploit can be found on my github
Timeline⌗
| Date (DD/MM/YYYY) | What |
|---|---|
| 07.10.2020 | Issue reported to [email protected] along with PoC exploit |
| 07.10.2020 | First response acknowledging the bug |
| 07.10.2020 | A first patch is proposed |
| 07.10.2020 | Final patch is proposed |
| 08.10.2020 | I verify the patch |
| 09.10.2020 | I verify the patch |